In this work I performed wordcloud visualization, sentiment analysis and topic modeling on the much anticipated database of Hilary Clinton’s leaked mails.
Data
The data consists of Hilary Clinton’s mails published during her campaign in the 2016 run for US President. To conduct NLP I need to create a converter between .csv format and .txt format to facilitate tokenization.
Wordcloud
It’s really quick to have a wordcloud running. However, data preprocessing makes a big difference as it will be visualized.
from wordcloud import WordCloud # pip install wordcloud
# set max words to 200 to simplify visualization
# .txt file generated from original .csv data
corpus = open('data/extractedMail.txt').read()
wordcloud = WordCloud(height=1000, width=2000, max_words=200).generate(corpus)
plt.figure(figsize=(20, 10)) # plot
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
Now you have a nice wordcloud here. There are clearly some meaningless words visible, so I’m going to clean up the text soon.
Preprocessing
Preprocessing is composed of the following steps:
- Tokenize the raw corpus.
- Delete stopwords from the tokenized corpus. Stopwords are cached in advance.
- Lemmatize and stem the corpus.
- Remove all punctuations.
The token returned are now ready for visualization and NLP.
from nltk.corpus import stopwords
from nltk.stem import WordNetLemmatizer
from nltk.stem.snowball import EnglishStemmer
def preprocessing(corpus, stopwords, verify=True):
# tokenize the corpus
# nltk.download('punkt')
token = nltk.word_tokenize(corpus)
# remove the stopwords
clean_token = [word for word in token if word not in stopwords]
# lemmatization
# nltk.download('wordnet')
lemmatizer = WordNetLemmatizer()
lemmatized_token = [lemmatizer.lemmatize(word) for word in clean_token]
# stemming
stemmer = EnglishStemmer()
stemmed_token = [stemmer.stem(word) for word in lemmatized_token]
# remove all the punctuations
no_punctuation_token = [word for word in stemmed_token if word not in string.punctuation]
# verify a bit the progress we made
if verify:
print('raw token size: ', len(token))
print('token size after preprocessing: ', len(no_punctuation_token))
return no_punctuation_token
So let’s do wordcloud again with the same set-up. Now it looks way better since most stopwords are removed.
Sentiment analysis
The second purpose of this study is to perform sentiment analysis, grouped by country, over the mails. pycountry can be used to detect country names in the mails. After tagging each mail with country names, sentiment analysis can be performed as follows.
from nltk.sentiment.vader import SentimentIntensityAnalyzer
# use compound value for polarity aggregation
extractedMail['Sentiment'] = np.nan
sid = SentimentIntensityAnalyzer()
def calc_sentiment(row):
# nltk.download('vader_lexicon')
if not extractedMail.loc[row, 'Countries']:
extractedMail.loc[row, 'Sentiment'] = 0.0
else:
vader_points = sid.polarity_scores(' '.join(extractedMail.loc[row, 'Tokens']))
extractedMail.loc[row, 'Sentiment'] = vader_points['compound']
for row in range(extractedMail.shape[0]):
calc_sentiment(row)
The visualization with seaborn looks as follows.
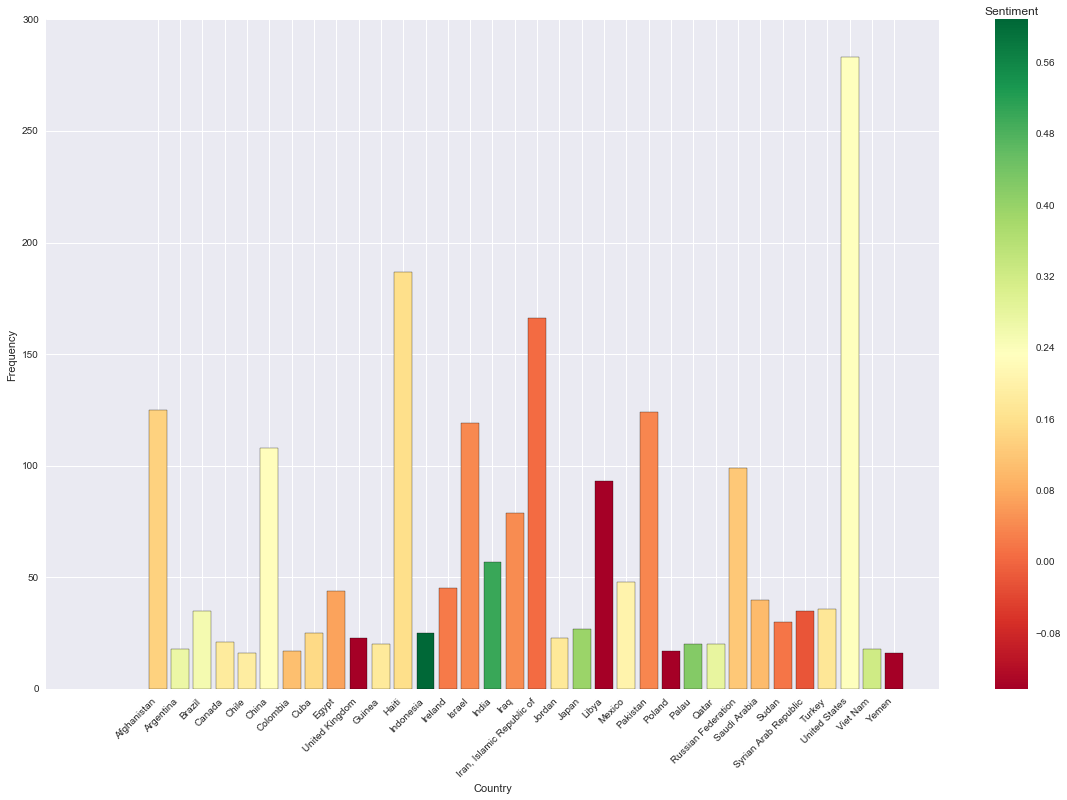
It’s surprising to see United Kingdom has such a low sentiment score. The other results generally accord with my expectation.
Topic modeling
The topic modeling part is reinforced by gensim and Latent Dirichlet Allocation(LDA) model. I have two jobs to do:
- Use gensim to generate topics with most relevant keywords.
- Remove meaningless stopwords and run TM again, on an iterative basis.
from gensim import corpora, models, similarities
# make and save dictionary
dictionary = corpora.Dictionary(iter_corpus)
dictionary.save('dictionary.dict')
# make and save corpus
final_corpus = [dictionary.doc2bow(text) for text in iter_corpus]
corpora.MmCorpus.serialize('corpus.mm', final_corpus)
# load
dictionary = corpora.Dictionary.load('dictionary.dict')
corpus = corpora.MmCorpus('corpus.mm')
# run
model = models.LdaModel(corpus, id2word=dictionary, num_topics=10)
model.print_topics()
The iter_corpus is the corpus generated at previous step but will be updated upon every TM step. I will kick out some stopwords after each TM step until I can see some evident topics.
[(0,
'0.010*"parti" + 0.007*"state" + 0.007*"presid" + 0.007*"obama" + 0.007*"polit" + 0.007*"american" + 0.006*"govern" + 0.006*"elect" + 0.005*"support" + 0.005*"year"'),
(1,
'0.029*"offic" + 0.028*"secretari" + 0.015*"depart" + 0.015*"boehner" + 0.013*"room" + 0.011*"arriv" + 0.011*"confer" + 0.010*"2010" + 0.010*"cheryl" + 0.010*"hous"'),
(2,
'0.018*"israel" + 0.014*"isra" + 0.011*"palestinian" + 0.009*"settlement" + 0.009*"tea" + 0.004*"news" + 0.004*"vote" + 0.004*"5" + 0.004*"reuter" + 0.004*"favor"'),
(3,
'0.048*"offic" + 0.040*"secretari" + 0.033*"depart" + 0.023*"state" + 0.018*"room" + 0.014*"rout" + 0.013*"arriv" + 0.013*"privat" + 0.013*"resid" + 0.012*"statement"'),
(4,
'0.020*"haiti" + 0.014*"state" + 0.012*"updat" + 0.008*"ashton" + 0.007*"press" + 0.007*"secretari" + 0.007*"clip" + 0.006*"secur" + 0.006*"hous" + 0.006*"202"'),
(5,
'0.012*"2010" + 0.008*"state" + 0.007*"part" + 0.006*"nuclear" + 0.006*"releas" + 0.006*"unit" + 0.006*"sent" + 0.005*"secur" + 0.005*"american" + 0.005*"pakistan"'),
(6,
'0.015*"speech" + 0.012*"huma" + 0.010*"yes" + 0.009*"abedin" + 0.009*"qddr" + 0.008*"draft" + 0.008*"2010" + 0.007*"\'m" + 0.006*"list" + 0.006*"cdm"'),
(7,
'0.011*"republican" + 0.009*"obama" + 0.008*"presid" + 0.007*"democrat" + 0.005*"afghanistan" + 0.005*"state" + 0.005*"year" + 0.005*"bill" + 0.005*"american" + 0.005*"senat"'),
(8,
'0.021*"state" + 0.014*"lona" + 0.012*"letter" + 0.012*"valmoro" + 0.011*"secretari" + 0.009*"tri" + 0.008*"iran" + 0.008*"amend" + 0.008*"assist" + 0.008*"2010"'),
(9,
'0.007*"woman" + 0.006*"obama" + 0.006*"state" + 0.005*"govern" + 0.005*"peopl" + 0.005*"public" + 0.005*"american" + 0.005*"clinton" + 0.004*"year" + 0.004*"polici"')]
Super! We can see some cool topics like number 2. It’s easy to identify the topic as Israel-Palestine conflict issues. Topic number 8 looks cool as well.
Credits
This work is part of my EPFL Applied Data Analysis Homework. The source code is served at Github.